Introduction
The database slowed down… and suddenly the entire app stopped working.
You've probably seen this before. One service gets sluggish. Response times climb. Thread pools fill up. And then, nothing. The whole thing goes dark.
What started as a slow database query ends as a full system outage.
This is one of the most common failure patterns in distributed systems:
One failing component takes down everything else.
And the frustrating part? The rest of the system was fine. It was just waiting on the one thing that couldn't respond.
The core idea here is this:
Systems should not aim to be perfect. They should aim to survive failure.
Because at scale, failure is not a question of if. It's a question of when.
This post walks through how to design systems that degrade instead of crash. We'll cover circuit breakers, fallbacks, feature flags, and the mindset shift that makes resilient systems possible.
1. Why Systems Fail Catastrophically
Most systems that crash completely don't have a single massive bug. They have a design that never accounted for partial failure.
Tight Coupling Between Services
When Service A directly calls Service B, and Service B calls Service C, you've built a chain. One broken link and the whole chain snaps.
If Service C starts taking 10 seconds to respond instead of 100ms, Service B blocks waiting for it. Service A blocks waiting for Service B. And your users are left staring at a spinner.
No Failure Boundaries
A failure boundary is something that stops a problem from spreading. Without them, failures propagate freely, from one service to the next, until the entire system is affected.
Blocking Dependencies
Synchronous calls to slow or unresponsive services hold resources captive. Threads block. Connection pools drain. Memory fills up.
Lack of Timeouts
This is more common than you'd think. A service makes an outbound call with no timeout configured. The dependency hangs. The thread hangs with it. Multiply that by your thread pool size and you have an outage.
The Cascade Effect
Here's the typical sequence:
- Dependency slows down
- Requests pile up waiting
- Thread pool exhausts
- New requests are rejected
- System-wide outage
One slow dependency caused it all.

2. What Does "Graceful Degradation" Mean?
Graceful degradation means a system continues to function with reduced capability instead of failing completely.
It's not about being perfect. It's about being useful even when things go wrong.
Examples
- Showing cached product data instead of live inventory
- Hiding the recommendations widget when the recommendation engine is down
- Accepting orders but delaying payment processing during a payment service outage
- Returning a generic response when personalization fails
The Car Analogy
Think about a car losing its air conditioning on a hot day. It's uncomfortable. It's not ideal. But you can still drive to your destination.
Contrast that with the engine dying. You're not going anywhere.
Graceful degradation is designing your system so that losing one component is like losing the AC, not the engine.
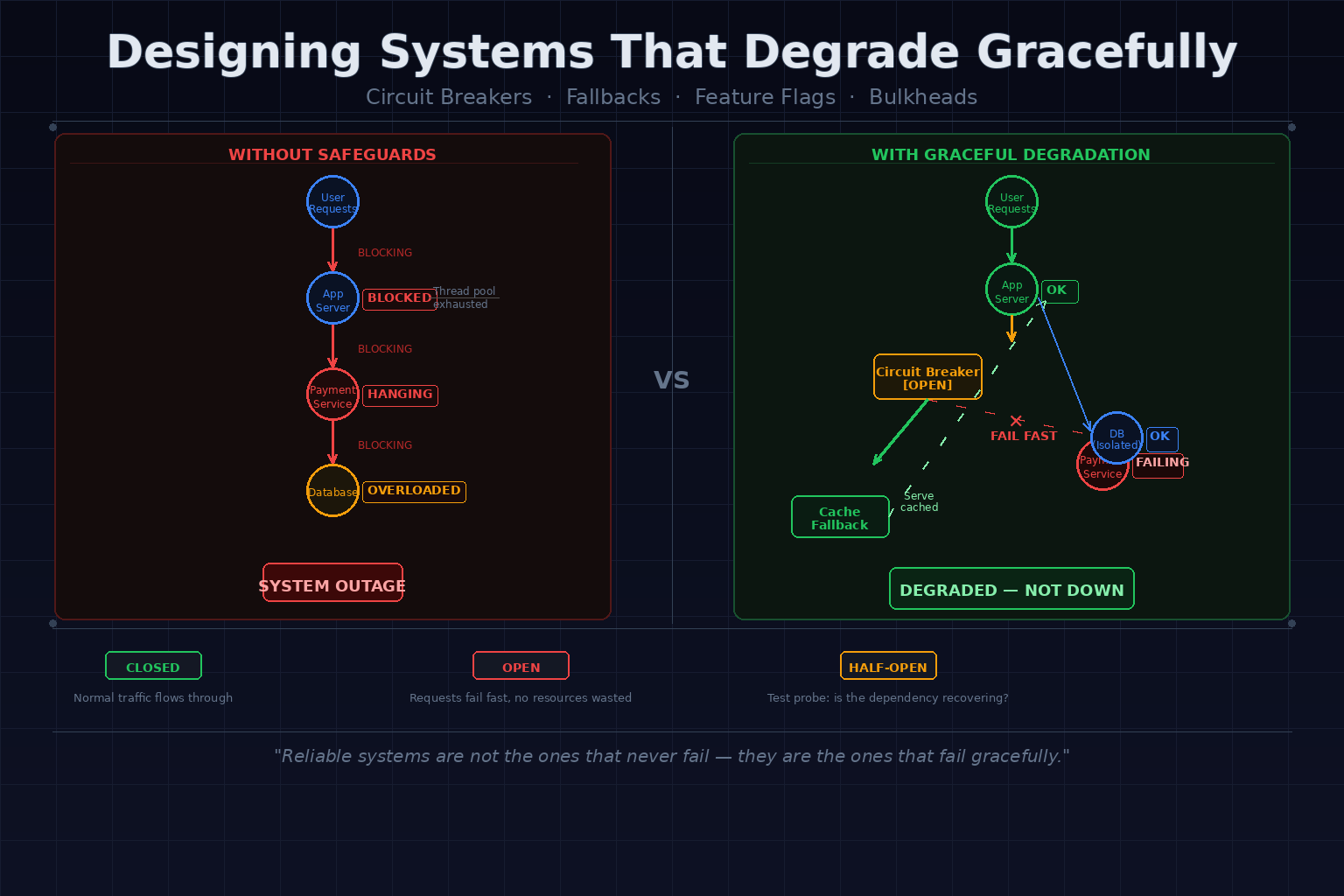
3. Circuit Breakers: Preventing System Collapse
A circuit breaker is one of the most important patterns in distributed systems resilience.
The name comes from electrical engineering. When a circuit gets overloaded, a breaker trips and stops the flow, preventing damage to the rest of the system.
In software, a circuit breaker wraps a call to an external dependency and monitors whether that call succeeds or fails.
The Three States
Closed (normal operation)
Requests go through as usual. Failures are counted. If failures exceed a threshold, the breaker opens.
Open (failing fast)
Requests are blocked immediately without even trying the dependency. The system returns an error (or a fallback) instantly instead of waiting for a timeout.
This is the key insight: failing fast is better than failing slowly.
Half-Open (testing recovery)
After a waiting period, a small number of requests are allowed through. If they succeed, the breaker closes again. If they fail, it stays open.
Why This Matters
Without a circuit breaker:
- 100 requests hit a failing service
- All 100 wait for the timeout
- 100 threads are held captive
- System is overwhelmed
With a circuit breaker:
- After a few failures, the breaker opens
- Subsequent requests fail fast
- Threads are freed immediately
- System remains responsive
The circuit breaker protects your system from spending resources on calls that have no chance of succeeding.
4. Fallbacks: Serving Something Instead of Nothing
A fallback is what your system does when the primary path fails.
The principle is simple:
A partial response is often better than no response.
Fallback Strategies
Default responses
Return a sensible default when the real data is unavailable. A search that can't query the catalog could return popular items instead of an error.
Cached data
If you can't fetch live data, serve what you cached earlier. It might be a few minutes stale. That's usually better than a blank screen.
Static content
During a personalization engine outage, serve non-personalized content. It's less relevant but it works.
Graceful UI degradation
Hide components that depend on failing services. Don't crash the page. Just remove the widget that can't load.
The Trade-off
Fallbacks come with a cost:
- Cached data may be stale
- Default responses lose accuracy
- Partial UIs look incomplete
But your system remains usable. Users can still accomplish their primary goal.
The goal isn't perfect data. It's a functioning system.
5. Feature Flags: Turning Off the Problem
Feature flags are runtime switches that control which parts of your system are active.
You deploy the code. But whether it runs is controlled by a flag.
Why Feature Flags Are Powerful
No redeploy needed.
During an incident, you don't have to push code, wait for a build, and roll it out. You flip a flag and the behavior changes immediately.
Immediate mitigation.
If a new feature is causing errors, you disable it in seconds. The system stabilizes while you investigate.
Granular control.
You can disable expensive features under load, gradually roll out fixes, or test new behavior with a subset of users.
Practical Use Cases
- Payment processing is degraded → disable the checkout flow, show "payments temporarily unavailable"
- Recommendation engine is overloaded → turn off recommendations site-wide
- A new feature is causing increased latency → disable it instantly without a rollback
- Traffic is spiking → disable non-critical background processing
Feature flags transform operational control from a deploy decision into a configuration decision.
That's an enormous difference when you're in the middle of an incident.
6. Timeouts, Retries, and Backpressure
These three concepts are the building blocks of resilient communication between services.
Timeouts
Every outbound call should have a timeout. No exceptions.
Without timeouts, a hanging dependency holds your thread indefinitely. Enough of those and your thread pool is gone.
A good timeout is just short enough to free resources before they accumulate, without being so short that legitimate slow responses are treated as failures.
Retries
Retries feel safe. "Just try again." But done wrong, they make things worse.
A failing service gets hit once. You retry. The service is still failing and now it gets twice the traffic. You retry again with a third attempt. Now three times the traffic is hitting an already-struggling service.
Multiply that across hundreds of clients and you've created a retry storm, effectively a self-inflicted DDoS.
Retries must be:
- Bounded: limited number of attempts
- Jittered: add randomness to prevent synchronized retries
- Exponentially backed off: wait longer between each attempt
Backpressure
Backpressure is the mechanism by which a loaded system says "slow down."
A queue fills up. A service rejects requests. A client reduces its send rate.
Without backpressure, a slow consumer gets overwhelmed by a fast producer and collapses.
With backpressure, the system self-regulates. The load distributes across time instead of all arriving at once.
7. Designing for Partial Failure
Here's the mindset shift that changes how you build systems:
Assume your dependencies will fail.
Not might fail. Will fail. It's only a matter of when.
Design each component to continue operating, even in a degraded state, when its dependencies are unavailable.
Isolation
Don't let failures in one area bleed into another. Each service should have clear failure boundaries. A crash in Service A should not automatically crash Service B.
Bulkheading
Named after ship design: partition the hull into separate compartments so that one breach doesn't sink the vessel.
In software, bulkheading means giving different features or consumers separate resource pools. If the recommendations service consumes all its threads, the checkout flow should be unaffected.
Shared thread pools, shared connection pools, shared caches. These are how failures spread. Isolate them.
Dependency Boundaries
Map out which components depend on which. Be explicit about:
- What happens when a dependency is slow
- What happens when a dependency is down
- What the acceptable fallback is
If you can answer these questions for every external call in your system, you're designing for failure correctly.
8. Real-World Failure Scenario Walkthrough
Let's make this concrete.
The Scenario
An e-commerce platform. Users can browse products, add to cart, and check out. The checkout flow calls an external payment service.
The payment service starts slowing down. Response times go from 200ms to 8 seconds.
Without Safeguards
Every checkout request waits 8 seconds for the payment service to respond.
Threads pile up. Connection pool to the database exhausts because threads are holding connections while waiting.
Now database queries from the product catalog also start failing.
Users can't browse products. Users can't search. The whole platform is down, all because of a slow payment service.
With Graceful Design
Circuit breaker on the payment service:
After a few slow/failed responses, the circuit breaker opens. Checkout requests fail immediately with a clear message: "Payments temporarily unavailable."
Feature flag for checkout:
The on-call engineer notices the circuit breaker is open. They flip a feature flag to disable checkout entirely and display a friendly message: "We're experiencing a payment processing issue. Please try again shortly."
Isolation of resources:
The payment service thread pool is separate from the product catalog thread pool. Threads exhausted waiting for payments don't affect browsing.
Fallback for product data:
Product catalog falls back to cached data for read-heavy operations. Users can browse, search, and view products normally.
Result:
- Checkout is temporarily disabled
- Users can still browse and add to cart
- The platform is stable
- On-call can investigate without a full outage in progress
One step from "everything is broken" to "core functionality still works."
9. Trade-offs of Graceful Degradation
Graceful degradation is not free. It comes with real costs that you should understand upfront.
Increased Complexity
Every fallback path is code that needs to be written, tested, and maintained. Circuit breakers need configuration. Feature flags need infrastructure.
Simple systems are easier to reason about. Resilient systems are more complex.
More Code Paths
The "happy path" is the easy part. You now have to handle:
- What happens when this call fails?
- What happens when it's slow?
- What do we show the user?
Each of these branches is a code path that can have bugs.
Harder Testing
How do you test that your circuit breaker opens at the right time? How do you test fallback behavior? How do you simulate partial failures?
It requires deliberate effort: chaos engineering, fault injection, resilience testing.
Requires Good Monitoring
A circuit breaker that trips silently is a system that's silently degraded. You need visibility into:
- Which circuit breakers are open
- How often fallbacks are being used
- What percentage of requests are hitting degraded paths
Without monitoring, graceful degradation becomes invisible degradation, and that's dangerous.
Is It Worth It?
Yes. For any system where reliability matters.
The complexity is real, but it's manageable. And it's far better than explaining to your users why everything broke because one downstream dependency was having a bad day.
10. A Practical Resilience Checklist
Use this as a starting point for auditing your systems:
Timeouts
- Every outbound HTTP call has a timeout configured
- Database queries have timeouts
- Queue consumers have message processing deadlines
Circuit Breakers
- Critical external dependencies are wrapped with circuit breakers
- Breaker states are observable (metrics, dashboards)
- Fallback behavior is defined for each breaker
Fallbacks
- Every critical user flow has a fallback path
- Cached data is available for read-heavy operations
- UI components degrade gracefully when data is unavailable
Feature Flags
- High-risk features are behind flags
- Expensive operations can be disabled at runtime
- Incident response includes flag-based mitigations
Retries
- Retry policies have limits
- Retries use exponential backoff with jitter
- Idempotency is guaranteed for retried operations
Monitoring
- Alert on circuit breaker state changes
- Track fallback usage rates
- Measure and alert on dependency latency
Conclusion
Failures are inevitable in distributed systems.
The services you depend on will go down. Networks will be slow. Databases will get overloaded. Something unexpected will happen at 2am on a Saturday.
What matters is how your system behaves when things go wrong.
The patterns in this post (circuit breakers, fallbacks, feature flags, timeouts, bulkheads) are not academic exercises. They are the difference between a brief degraded experience and a full outage.
They are what lets your on-call engineer flip a switch instead of fighting a production fire.
Start small. Pick one critical dependency. Ask: what happens when this is slow? What happens when it's down? What should we show the user?
Answer those questions. Then build the answer into your system.
Because in the end:
Reliable systems are not the ones that never fail.
They are the ones that fail gracefully.